
GitHub Copilot is Moving to Usage-Based Billing from June 1, 2026
Premium Requests are being replaced by GitHub AI Credits — here's what changes for every plan, with the math, examples, and a before/after breakdown.
I’m Siddhesh, a Microsoft Certified Trainer, cloud architect, and AI practitioner focused on helping developers and organizations adopt AI effectively. As a Pluralsight instructor and speaker, I design and deliver hands-on AI enablement programs covering Generative AI, Agentic AI, Azure AI, and modern cloud architectures.
With a strong foundation in Microsoft .NET and Azure, my work today centers on building real-world AI solutions, agentic workflows, and developer productivity using AI-assisted tools. I share practical insights through workshops, conference talks, online courses, blogs, newsletters, and YouTube—bridging the gap between AI concepts and production-ready implementations.
If you use GitHub Copilot, your bill is about to start working very differently. Starting June 1, 2026, Copilot stops counting "premium requests" and starts charging based on how much the AI model actually works for you.
This post walks through what changes, decodes the jargon, and shows the math with real examples so you can figure out whether your wallet will feel it.
First, let's decode the jargon
Before we get into "before vs after," here are the words you'll keep seeing.
Token — a chunk of text the AI model reads or writes. Roughly 1 token ≈ 4 characters of English, or about ¾ of a word. "Hello, world!" is ~4 tokens.
Input tokens — what you (and your code, files, chat history) send into the model.
Output tokens — what the model sends back.
Cached tokens — context the model has already seen and can reuse cheaply (e.g., the same big file in a long chat). Cached tokens are billed at a much lower rate.
Premium Request (PRU) — the old unit. One "request" you make to a premium model. Different models had a multiplier (e.g., a heavy model = 5 requests, a frontier model = 50 requests).
GitHub AI Credit — the new unit. 1 AI Credit = \(0.01 USD. So 100 credits = \)1, and 1,900 credits = $19.
Pooled credits — instead of each user getting their own bucket, the whole organization shares one big bucket of credits.
Fallback model — when you ran out of premium requests, Copilot used to silently downgrade you to a cheaper model so you could keep working. This is going away.
Code completions / Next Edit Suggestions — the gray "ghost text" that auto-completes as you type. These stay free and unlimited on all paid plans. Nothing in this post applies to them.
The 30-second summary
| Before June 1, 2026 | After June 1, 2026 | |
|---|---|---|
| Billing unit | Premium Requests (PRUs) | GitHub AI Credits (1 credit = $0.01) |
| What's measured | A "request" × model multiplier | Actual input + output + cached tokens |
| Run out of allowance | Falls back to cheaper model, keep working | No fallback. Either pay overage or get blocked |
| Code completions | Free, unlimited | Free, unlimited (unchanged) |
| Plan prices | \(10 / \)39 / \(19 / \)39 | Same prices — but you now get $X of credits |
| Org-wide sharing | Each user has own quota | Credits pooled across the org |
| Budget controls | Limited | Granular: enterprise / org / cost center / user |
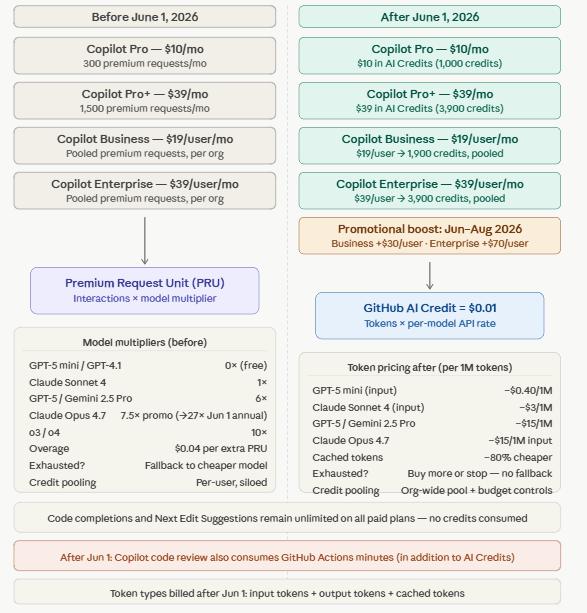
Plan prices are not changing. What's changing is what you get for that money and how it gets consumed.
Before / After at a glance — all plans

The diagram above maps every plan from the old PRU world to the new AI Credit world. Below are the same details as plain tables, in case you want to skim or copy values.
Per-plan changes
| Plan | Before June 1, 2026 | After June 1, 2026 | Promo (Jun–Aug 2026) |
|---|---|---|---|
| Copilot Pro — $10/mo | 300 premium requests/mo | 1,000 AI Credits ($10) | — |
| Copilot Pro+ — $39/mo | 1,500 premium requests/mo | 3,900 AI Credits ($39) | — |
| Copilot Business — $19/user/mo | Per-user PRU quota | 1,900 credits/user, pooled | 3,000 credits/user, pooled |
| Copilot Enterprise — $39/user/mo | Per-user PRU quota | 3,900 credits/user, pooled | 7,000 credits/user, pooled |
Model multipliers (before) vs token rates (after)
| Model | Before (PRU multiplier) | After (illustrative per-1M-token rate) |
|---|---|---|
| GPT-5 mini / GPT-4.1 | 0× (free) | ~$0.40 / 1M input |
| Claude Sonnet 4 | 1× | ~$3 / 1M input |
| GPT-5 / Gemini 2.5 Pro | 6× | ~$15 / 1M input |
| Claude Opus 4.7 | 7.5× promo (→27× on annual plans Jun 1) | ~$15 / 1M input |
| o3 / o4 | 10× | (per published model rate) |
| Cached tokens | n/a | ~5–10× cheaper than fresh input |
| Overage | $0.04 per extra PRU | Buy more credits, or stop — no fallback |
| Credit / quota pooling | Per-user, siloed | Org-wide pool + budget controls |
Always check GitHub's Models and pricing page for the live per-token rate for the model you actually use. Numbers above are illustrative.
How a single request is billed
| Step | Before June 1 | After June 1 |
|---|---|---|
| 1. You send a chat / agent task | Counted as 1 request | Model reads input + writes output + reuses cached tokens |
| 2. Cost rule | 1 × model_multiplier PRUs |
tokens × per-model API rate, then ÷ $0.01 to get credits |
| 3. Deducted from | Your monthly PRU quota | The pooled AI Credit pool |
| 4. Quota / pool empty? | Falls back to cheaper model, you keep working | No fallback. Either pay overage at published rate, or get blocked until next cycle |
| 5. Code completions / Next Edit Suggestions | Free, unlimited | Free, unlimited (unchanged) |
| 6. Copilot code review | Premium request | AI Credits + GitHub Actions minutes |
Mapping the old world to the new world
There is no exact 1-to-1 conversion from a Premium Request to AI Credits — and that is the whole point of the change. A "request" used to cost the same whether it was a one-line question or a 3-hour autonomous coding agent run. Now you pay for what the model actually crunches.
That said, here's a rough mental model so you can translate quickly:
| Plan | Old monthly quota | New monthly credits | New $ value | Implied "average" credits per old request |
|---|---|---|---|---|
| Pro | 300 PRUs | 1,000 credits | $10 | ~3.3 credits ≈ $0.033 |
| Pro+ | 1,500 PRUs | 3,900 credits | $39 | ~2.6 credits ≈ $0.026 |
| Business | 300 PRUs / user | 1,900 / user (pooled) | $19 | ~6.3 credits ≈ $0.063 |
| Enterprise | 1,000 PRUs / user | 3,900 / user (pooled) | $39 | ~3.9 credits ≈ $0.039 |
Reality is messier than that table because a "request" isn't a flat thing anymore. A small chat may cost 0.2 credits. A long agent session on a frontier model may cost 30+ credits. Two people on the same plan can have wildly different bills.
How costs are actually calculated — with examples
Before June 1 (Premium Request math)
cost in PRUs = 1 request × model_multiplier
You don't pay per token; you pay one "request" no matter how big it is. Multipliers (illustrative — exact values are in GitHub's model table):
GPT-4o, Claude Sonnet → 1×
o1-mini → ~0.33×
GPT-4.5 → ~50×
Claude Opus → ~10×
Example A — Quick chat question on GPT-4o (Pro user)
1 request × 1× multiplier = 1 PRU
Out of monthly 300 → 299 left.
It does not matter whether you sent 50 tokens or 50,000 tokens.
Example B — Big agent run on GPT-4.5 (Pro user)
1 multi-step agent task that took 45 minutes and processed 200,000 tokens.
Still counted as 1 request × 50× multiplier = 50 PRUs.
Out of 300 → 250 left, regardless of how heavy the actual compute was.
This is why GitHub says the model "is no longer sustainable" — heavy agent runs were dramatically underpriced compared to chat.
After June 1 (AI Credits math)
cost in $ = (input_tokens × input_rate)
+ (output_tokens × output_rate)
+ (cached_tokens × cached_rate)
cost in credits = cost in \( / \)0.01
The rates are the same as the public API rates for that model. Cached tokens are typically 5–10× cheaper than fresh input tokens.
The numbers below use illustrative per-million-token rates to show the math. Always check GitHub's Models and pricing page for the live rates of the model you use.
Example A — Quick chat question (same as before) Assume GPT-4o-class model: input \(2.50 / 1M tokens, output \)10 / 1M tokens.
Input: 500 tokens → 500 × \(2.50 / 1,000,000 = \)0.00125
Output: 200 tokens → 200 × \(10 / 1,000,000 = \)0.002
Total: $0.00325 → about 0.33 credits
You can do this ~3,000 times on a Pro plan ($10 / 1,000 credits). Compare that to 300 under the old model — small interactions get cheaper.
Example B — Heavy agent run (same as before) Assume a frontier model: input \(15 / 1M, output \)75 / 1M, cached $1.50 / 1M.
Input (fresh): 30,000 tokens → $0.45
Cached input: 170,000 tokens → $0.255
Output: 20,000 tokens → $1.50
Total: $2.205 → about 220 credits
Under the old model that was 50 PRUs (1/6 of your monthly Pro quota). Under the new model it's 22% of your monthly Pro credits. Agent-heavy work gets more expensive — which is exactly the rebalancing GitHub is going for.
Example C — A team of 50 on Copilot Business
Pool = 50 × 1,900 = 95,000 credits / month ($950 of usage).
Promo period (Jun–Aug): 50 × 3,000 = 150,000 credits / month.
Heavy users can dip into lighter users' unused share — no more stranded capacity at the per-seat level.
Admin can set a per-user cap (say, 4,000 credits) so one engineer can't drain the pool.
Hit the pool ceiling? Either pay overage at published per-credit rates, or get blocked till next cycle. No silent fallback.
Example D — Code completions all day
Tokens flying back and forth as you type.
Credits consumed: 0. Completions and Next Edit Suggestions remain free on all paid plans.
What this means for you
Light chat user, Pro plan → Likely a win. 300 requests becomes effectively thousands of small chats.
Heavy agent user, Pro plan → Likely more expensive per task. Watch your credit balance, especially with frontier models.
Annual Pro / Pro+ subscribers → You stay on the old PRU model until your annual renewal. Heads up: model multipliers go up on June 1 for annual plans only.
Business / Enterprise admin → You get pooled credits and four levels of budgets (enterprise, org, cost center, user). Set a user-level budget; a $0 user budget = no Copilot for that user.
Anyone relying on the fallback to a cheaper model → That door is closed. Plan for it.
A preview bill lands in early May 2026 in your Billing Overview, so you can see projected costs before the switch.
The mental model to walk away with
Old world: A "request" was a flat token, and the model multiplier was the only knob. You got a fixed number of these per month, and Copilot quietly downgraded you when you ran out.
New world: Every call costs real money based on real tokens, converted to AI Credits. Your plan price buys you a wallet of credits. Orgs share one big wallet. Admins set the rules. When the wallet is empty, you either top up or stop.
It's the cloud-billing model coming for AI tooling — pay for the compute you actually used. If your Copilot usage looks like "ask a quick question, accept a completion," your bill probably gets friendlier. If it looks like "spawn 10 autonomous agents on Friday night," it's about to get costlier.
Sources
GitHub Blog: GitHub Copilot is moving to usage-based billing
GitHub Docs: Usage-based billing for organizations and enterprises
GitHub Docs: Models and pricing for GitHub Copilot




